
Published: 07.11.2025
Estimated reading time: 30 minutes
Synthetic Data & Simulation
Fueling Analytics with Generative Models

Understanding Synthetic Data and Why It’s Needed
In today’s AI-driven world, data is the fuel of analytics – but often the “fuel” is in short supply or too sensitive to use. Synthetic data offers a solution. Synthetic data refers to artificially generated datasets that faithfully mirror the statistical properties of real data without using any actual real-world records. In other words, it’s fake data that looks and behaves like the real thing. Because it’s created from scratch by algorithms (rather than collected from real events or people), synthetic data can be made to preserve patterns and relationships in the original data while removing or anonymizing any sensitive details. This makes it extremely valuable when organizations face data scarcity or privacy constraints.
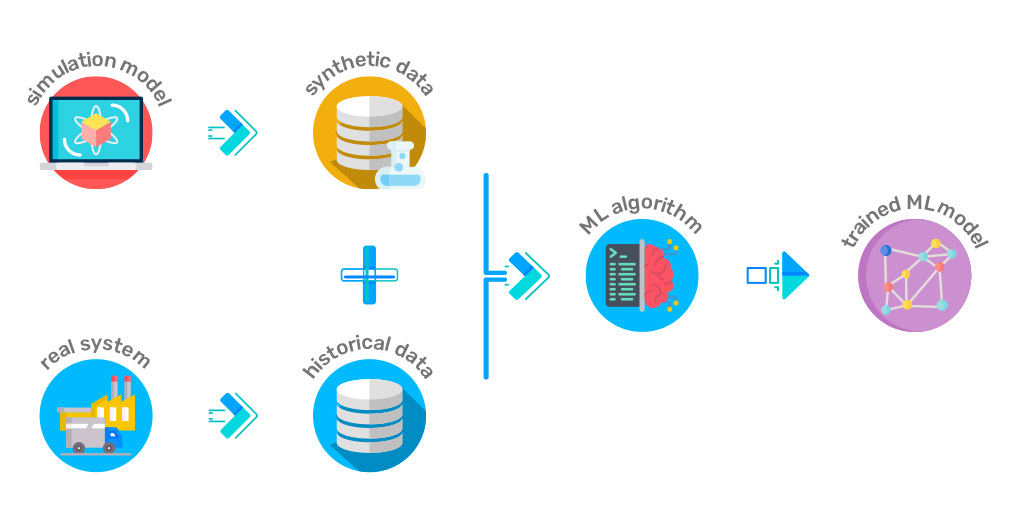
Why do we need synthetic data? Two big reasons are data availability and privacy. In many cases, real datasets are insufficient or hard to obtain. For example, a startup trying to build a machine learning model might not have enough historical data, or certain important scenarios (like fraudulent transactions or rare device failures) happen so infrequently that there isn’t enough real data to train a robust model. Synthetic data can fill these gaps by generating additional examples that are statistically realistic. The result is richer training data that can improve model performance even when real data is limited or imbalanced.
Privacy is the other major driver. In fields like healthcare and finance, strict regulations and ethical concerns often prevent sharing or using real personal data. Patient records or customer financial histories are sensitive, and even anonymized real datasets carry the risk of re-identification. Synthetic data sidesteps this issue by producing new records that contain no real personal identifiers, yet still reflect the patterns of the original data. This means analysts can work with, say, a synthetic patient database or transaction log that behaves like the real data without exposing any individual’s information. Companies can share synthetic datasets with partners or across departments freely, accelerating collaboration and innovation while staying compliant with privacy laws. In fact, industry analysts are so optimistic about synthetic data that Gartner predicts it will overshadow real data in AI by 2030, becoming a cornerstone of model training in the coming years. In short, synthetic data enables organizations to leverage data-hungry analytics and AI solutions even when real data is scarce, confidential, or costly to obtain, unlocking new possibilities.
Generative Techniques for Synthetic Data
How do we create synthetic data? The answer lies in generative models – advanced AI algorithms that can learn the patterns in real datasets and then produce new, similar data points. Over the last decade, generative modeling has evolved rapidly, giving rise to powerful techniques that can synthesize everything from realistic images to structured tables of information. Below, we review three leading generative approaches driving synthetic data creation: Generative Adversarial Networks (GANs), diffusion models, and transformer-based simulations. Each of these techniques has unique strengths and is often suited for particular data types (tabular, image, time-series, etc.).
GANs: Adversarial Generation of Data
Generative Adversarial Networks (GANs) are one of the pioneering tools for synthetic data generation. A GAN consists of two neural networks — a generator and a discriminator — locked in a creative duel. The generator’s job is to produce fake data (whether that be images, transaction records, etc.), while the discriminator’s job is to examine data and judge whether it is real or synthetic. Through an adversarial training process, the generator learns to create increasingly realistic data points, because it gets feedback from the discriminator on what looks fake versus what looks real. Over many iterations, a well-trained GAN can produce synthetic outputs that are indistinguishable from authentic data to the discriminator (and often to humans as well).
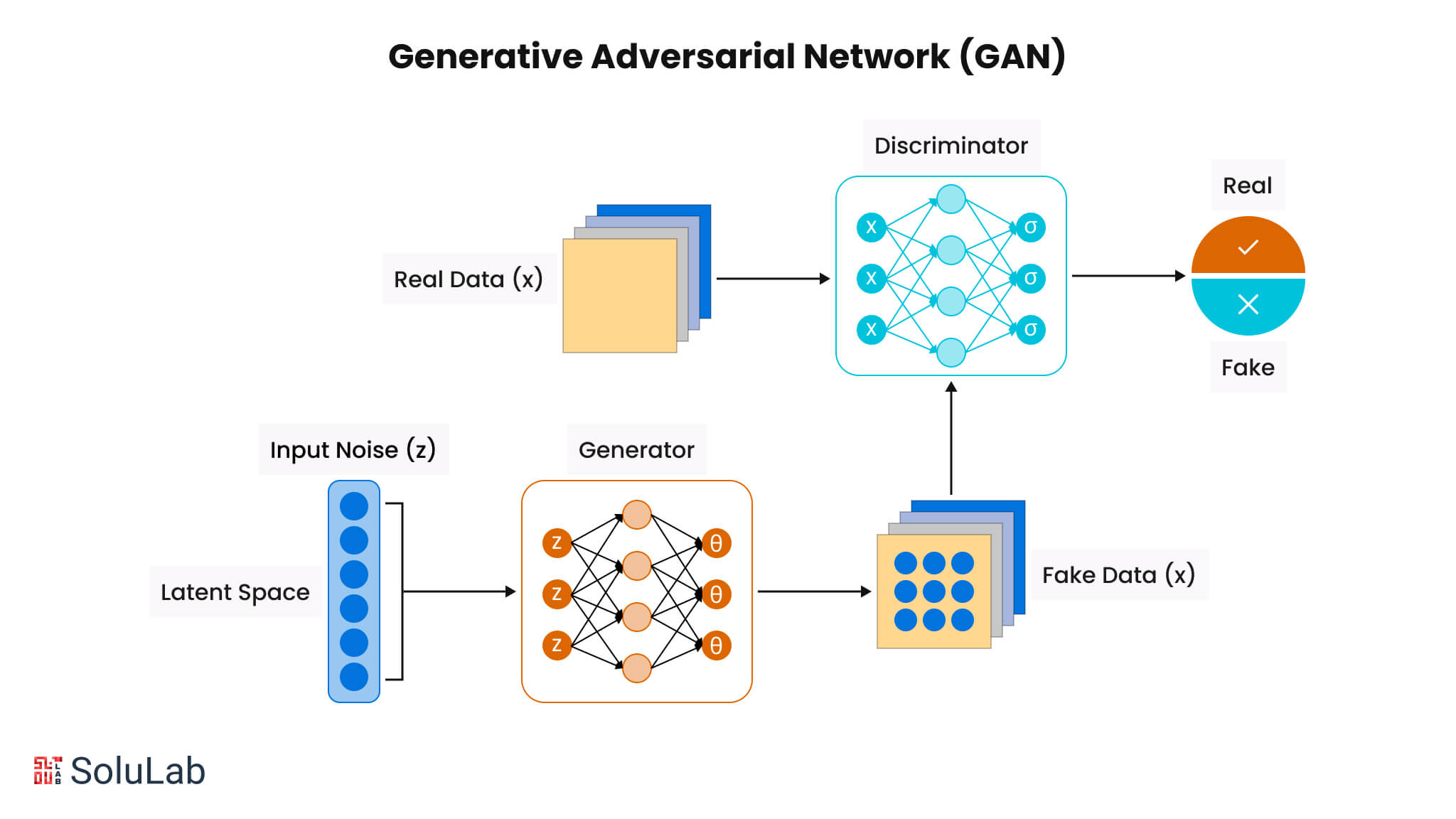
GANs first rose to fame by generating remarkably realistic images – think of photorealistic human faces that don’t belong to any real person. However, GANs are not limited to images. Researchers have developed GAN variants for other data modalities too. For example, CTGAN (Conditional Tabular GAN) is a GAN architecture tailored for tabular data (rows and columns, like you’d see in spreadsheets or databases). It can learn the distributions of each column and the correlations between them to generate synthetic records that respect the original data’s schema and properties. There are also time-series GANs (like TimeGAN) that specialize in sequential temporal data. Overall, GANs have proven to be extremely effective for high-dimensional, complex data. They excel at capturing intricate non-linear relationships, which makes them well-suited for generating things like high-resolution images, sequences of sensor readings, or multi-feature records. The realism of GAN outputs has been a game-changer – for instance, a GAN can generate thousands of synthetic credit card transactions or network events that feel as random and varied as real events, providing rich data to train fraud detection or cybersecurity models.
Despite their power, GANs do have some challenges (such as training instability or the possibility of mode collapse, where they might fail to produce diverse outputs). But with improvements and the ability to condition GANs on specific attributes (e.g. generating data for a certain class or demographic), they remain a cornerstone of synthetic data generation in practice.
Diffusion Models: Synthesizing Data by Refining Noise
Diffusion models are a newer class of generative model that have quickly become stars in the image synthesis arena. They take a very different approach from GANs. The basic idea of a diffusion model is to start with pure random noise and gradually refine it into structured data through a series of small denoising steps. During training, the model learns how to corrupt real data by adding noise in many incremental steps (diffusing the data into noise), and more importantly learns how to reverse that process (hence also called denoising models). When generating new data, the model begins with a random noise sample and then applies its learned denoising transformations step by step, eventually pulling an intelligible, realistic sample out of the noise. This process might sound slow, but it leads to incredibly detailed outputs – diffusion models have produced some of the most photorealistic images to date by iteratively “painting” the image with fine details.

The diffusion approach has proven especially powerful for images and other complex distributions because it doesn’t force the model to learn the data generation in one giant leap; instead, the model focuses on one noise-removal step at a time. The results have been spectacular in imaging (for example, the now-famous Stable Diffusion and related models can create high-fidelity images from text prompts, and they rely on this denoising diffusion principle). Now, diffusion models are being adapted beyond images, into tabular and time-series domains as well. Researchers have started to show that diffusion-based generators can produce quality synthetic data for things like financial time series or other sensor data, often preserving fine-grained patterns. In fact, recent advances indicate that diffusion models, along with other large-scale generative frameworks, are raising the bar for synthetic data fidelity across modalities including images, text, and structured data. The appeal of diffusion models for tabular or time-series data is that they might capture subtler statistical nuances that some GANs or other methods miss, potentially producing more realistic variation in the synthetic datasets. While this is an active area of research, the early results are promising – we’re beginning to see diffusion-based synthetic data generators that can match or even surpass GAN-based methods in certain metrics of realism.
Transformer-Based Simulation: Generating Sequences with Large Models
Transformers have revolutionized the field of AI in recent years, especially in natural language processing. These models – exemplified by the likes of GPT-4 – use a self-attention mechanism to learn long-range dependencies in sequential data. While transformers are most famous for generating text (like convincing human-like sentences and paragraphs), the same technology can be harnessed to generate other types of data as well. In the context of synthetic data, transformer-based models can simulate sequences and structured records by learning the “language” of the dataset.
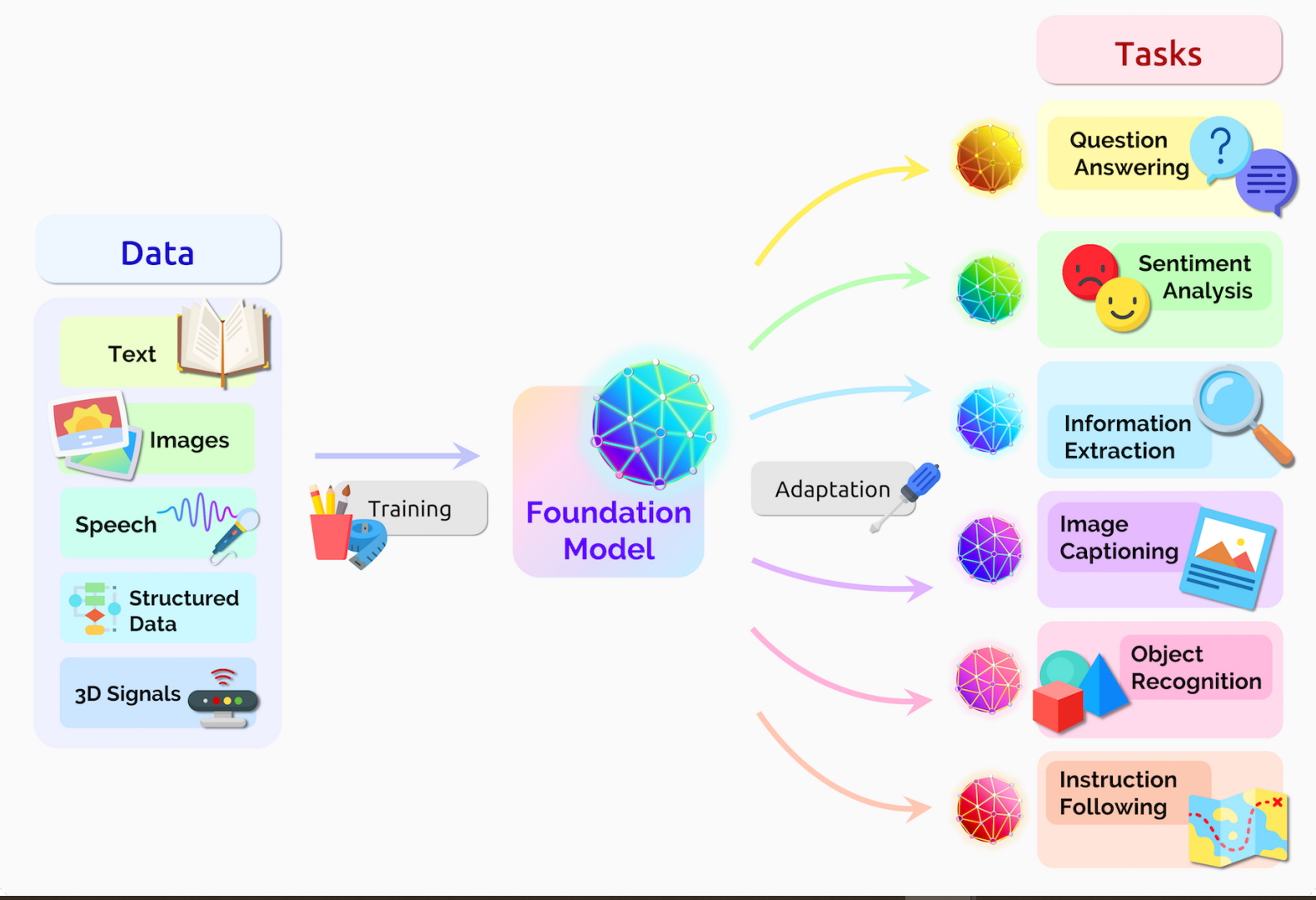
How does this work? A transformer model can be trained on existing data records (for example, a series of events, or rows from a database treated as sequences) by representing those records in a sequential manner. During training it learns the probability distribution of what comes next given what came before (much like learning to predict the next word in a sentence). Then the model can generate new sequences by iteratively sampling next values. This approach has proven useful for generating synthetic text data (chat logs, paragraphs, etc.), but also for things like log data, code, or any data that can be serialized in sequence form. Because transformers are so good at capturing context and relationships, a large pre-trained transformer can be conditioned or fine-tuned to output very realistic synthetic data records. For instance, one could use a transformer to generate synthetic patient records one field at a time, or to simulate time-series sensor readings one timestamp at a time, maintaining coherence over long sequences.
One advantage of transformer-based generation is flexibility – with the right conditioning, a single model can potentially generate a variety of outputs (for example, a prompt-based approach: “generate a dataset with X properties” to guide the output). In practice, we see transformers being used to create synthetic text and even tabular data when appropriately set up. As foundation models (large pre-trained transformers) become more widespread, they are starting to be applied to data synthesis tasks. For example, a transformer might generate synthetic network traffic logs for cybersecurity testing, or simulate customer sequences (clickstreams, purchase histories) for business analytics, all while obeying the learned statistical patterns of the real data. This is sometimes called simulation because the model is effectively simulating the behavior of an underlying process (language, user activity, etc.) through generation.
It’s worth noting that simpler generative methods also exist (such as variational autoencoders or even straightforward statistical simulations like sampling from fitted distributions or using copulas). In fact, many practical synthetic data tools use a combination of techniques. But GANs, diffusion models, and transformers represent the cutting edge of AI-driven data synthesis. These generative models are the engines that enable us to create rich synthetic datasets for a wide range of applications.
Use Cases Powered by Synthetic Data
Synthetic data isn’t just a theoretical concept – it’s actively fueling analytics and AI solutions in a variety of fields. By providing extra (or safer) data, synthetic datasets allow projects to move forward where they otherwise might stall due to lack of data or privacy issues. Let’s look at a few prominent use cases where synthetic data is making a significant impact: fraud detection, healthcare research, and predictive maintenance. These examples illustrate how artificially generated data can unlock new possibilities and improvements in different industries.

Fraud Detection and Financial Risk Modeling
In finance and e-commerce, detecting fraudulent transactions or activities is a classic “needle in a haystack” problem – fraud incidents are relatively rare and often look quite different from regular behavior. This scarcity of fraud examples makes it challenging to train reliable detection models, because traditional machine learning needs lots of examples of each class (fraud vs. normal) to learn patterns effectively. Synthetic data is a game-changer for fraud analytics. By generating realistic fake transaction records, banks and payment companies can dramatically expand their training datasets for fraud detection. For example, if only a few dozen instances of a certain scam are present in the real data, a generative model could create thousands of plausible new instances of that scam, giving the fraud detection algorithm much more to learn from. These synthetic fraud examples can cover a wide variety of fraudulent patterns and edge cases, including ones that haven’t actually been observed yet but are theoretically possible.

The result is more robust fraud models that can catch novel tactics. Indeed, one report notes that since genuine fraud cases are so rare, “synthetic datasets can simulate a wide variety of fraudulent patterns, enabling fraud detection algorithms to be trained and tested more effectively. This applies not only to credit card transactions, but also to insurance claims fraud, anti-money-laundering (AML) monitoring (where synthetic banking transactions can help test AML systems), loan application fraud, and beyond. Financial institutions are even using synthetic customer data to test how changes in behavior might trigger alerts, all in a safe sandbox. The benefit of synthetic data in fraud and risk is twofold: it provides volume and diversity (more examples to catch more schemes) and it avoids privacy issues, since real customer data can be too sensitive to freely share for consortiums or vendor evaluations. By training on a mix of real and synthetic fraud data, analytics teams can improve detection rates while minimizing false alarms, all without endangering any real customer’s privacy.


Healthcare and Medical Research
Healthcare data is notoriously sensitive and protected – yet the insights hidden in patient data are incredibly valuable for improving care and advancing research. Synthetic data is emerging as a crucial tool in the healthcare domain by allowing researchers and practitioners to work with realistic patient information without risking patient privacy. For example, hospitals can generate a synthetic dataset of electronic health records that maintains the statistical patterns of diseases, lab results, and outcomes present in the real patient population, but none of the entries correspond to an actual individual. This synthetic patient database can then be shared with researchers or used to develop machine learning models (for predicting disease risk, optimizing treatments, etc.) without violating HIPAA regulations or GDPR. It essentially enables data-sharing and analytics collaboration in healthcare that would otherwise be stymied by privacy laws.

One key use case is in clinical trials and biomedical research. When starting a new clinical trial or medical study, researchers often need to simulate various scenarios (like patient response rates or disease progression under different conditions). Synthetic data can help project these scenarios before real-world data is available. For instance, using partially synthetic data, one could augment limited trial data to better plan patient recruitment or identify potential side effects early. IBM has noted that medical researchers are using partially synthetic data for clinical trials and fully synthetic data to create artificial patient records or medical images for developing treatments. Another area is medical imaging: generative models can produce synthetic MRI or CT scan images that resemble real scans, which can be used to train diagnostic algorithms when real annotated images are scarce.
Beyond research, synthetic health data enables safer internal and external data sharing. Within large healthcare systems, different departments or partner organizations might need to access patient data for analytics (operations, quality improvement, etc.), but sharing real data is risky. Synthetic datasets allow these groups to get value from the data without ever seeing a real person’s information. As one analysis put it, synthetic data lets healthcare data professionals enable internal and external data use while maintaining patient confidentiality. This approach preserves the utility of the data (the trends and correlations that drive insights) but eliminates personal identifiers that raise privacy concerns. The end result: faster research breakthroughs, improved predictive models for patient care, and more collaborative innovation across institutions – all achieved in an ethical and privacy-preserving way.
Predictive Maintenance and IoT Analytics
Industrial operations – from manufacturing plants to utility grids – increasingly rely on predictive maintenance analytics to keep equipment running smoothly. The idea is to use sensor data and machine learning to predict when a machine might fail or need servicing, so that maintenance can be done proactively (avoiding costly downtime or accidents). However, one practical challenge is that failures are (hopefully) rare events, and new equipment doesn’t have a long history of breakdowns to learn from. This is where synthetic data becomes extremely useful: engineers can generate synthetic sensor data that simulates equipment degradation, anomalies, and failure patterns to augment the limited real data they have.

For example, suppose you have built an AI model to monitor vibrations in a turbine to predict when it will fail. If the turbine design is new, you might have very few actual failure examples in your dataset. By creating a physics-informed simulation or using a generative model, you can produce many synthetic vibration sequences that lead up to a variety of failure modes. These synthetic sequences mimic how the real signals behave when the machine has, say, an engine imbalance or a worn-out bearing. Training your predictive maintenance model on this enriched dataset (real plus synthetic) can significantly improve its ability to catch warning signs. Synthetic sensor data can cover lots of “what-if” failure scenarios that haven’t occurred yet in reality but could occur in the future. According to one survey of use cases, synthetic data helps here by simulating equipment degradation patterns or fault signals, allowing predictive maintenance models to be trained before sufficient real-world failure data exists. This means companies can deploy reliable monitoring earlier in a machine’s life cycle, rather than waiting for years of historical failures to accumulate.
Another benefit is testing and validating maintenance systems. Companies can feed synthetic failure events into their monitoring software to ensure the alerts trigger correctly and the system responds as expected – a form of virtual stress testing for their algorithms. We also see synthetic data used for wider industrial IoT analytics, such as optimizing supply chains (simulating demand spikes or transportation delays), or improving quality control (creating synthetic defect images to train visual inspection systems). In all these cases, synthetic data provides the scale and variety needed for robust analytics, without risking disruption to actual operations (since you’re not running machinery to failure just to get data). The end result is smarter, more resilient industrial AI solutions that can save money and increase safety.
Checklist
Validating Synthetic Data Quality and Ethical Use

Generating synthetic data is only half the battle – the other half is making sure that data is truly useful and used responsibly. Just because data is synthetic doesn’t automatically guarantee it’s good or safe. Poor-quality synthetic data can mislead models, and unethical practices (even inadvertent ones) in generation can introduce bias or privacy issues (for example, if a generative model “leaks” parts of the real data it was trained on). Before deploying synthetic data in analytics, it’s crucial to validate its quality and ensure ethical standards are met. Below is a checklist of key steps and considerations for vetting synthetic data:
Check for Bias Amplification
Analyze the synthetic data for any signs of bias, especially in comparison to the original real data. Sometimes the process of generation can unintentionally amplify existing biases or create new ones. For example, if the real dataset had slightly imbalanced demographics, an unconstrained generator might exacerbate that imbalance in the synthetic output. It’s important to run the same bias and fairness analyses on synthetic data that you would on real data. If your synthetic population of loan applicants, for instance, shows unexplained discrepancies in approval rates between groups, that’s a red flag. You want synthetic data to reflect reality, not distort it further. As part of this step, ensure you follow ethical prompt-engineering guidelines (when applicable) and other responsible AI practices during generation – i.e. craft the generation process and prompts to avoid introducing stereotypes or sensitive attributes unwittingly. The goal is that your synthetic data does not introduce or amplify unfair biases beyond what was present (unless you intentionally debias it, which is another use-case of synthetic data). If biases are detected, you may need to adjust your generative model (e.g., re-balance the training data or apply bias mitigation techniques) and regenerate.
Ensure Balanced Coverage of Data Segments
Determine whether your synthetic data needs to deliberately balance certain segments or outcomes. One advantage of synthetic generation is the ability to boost underrepresented cases. For instance, in fraud modeling or rare disease research, you might specifically generate more examples of the rare class to give it equal footing in training. Check if your use case would benefit from this. If yes, verify that the synthetic data successfully increases the representation of those minority classes or edge cases in a realistic way. This can involve augmenting the data for historically under-served groups or rare events so that your models don’t overlook them. On the other hand, if synthetic data was intended to just mirror the original distribution, confirm that it hasn’t unintentionally skewed the balance. In short, use synthetic data strategically to either match or intentionally adjust the distribution of the real data, depending on the goal, and verify those adjustments are correctly implemented.
Validate Privacy and Security
Even though synthetic data is designed to protect privacy, it’s wise to double-check that no sensitive information has leaked. A well-known risk is that a generative model might overfit and output something too similar to a real record (especially if the model was trained on a small dataset). Perform tests like searching for any records in synthetic data that are exact or near matches to records in the source data. Employ privacy metrics if available – for example, measures of re-identification risk or a membership inference test (which checks if an attacker could tell whether a particular real person’s data influenced the model). It’s also recommended to apply techniques like differential privacy during generation if working with highly sensitive data – this injects statistical noise to provide formal privacy guarantees. Additionally, treat your synthetic data with good data security practices: although it may not refer to real individuals, it could still be sensitive (for example, synthetic financial transactions could reveal how your fraud detection system works). Thus, secure the synthetic data against unauthorized access just as you would real data. Some organizations use a “vulnerability score” or similar assessments to rate how secure a synthetic dataset is. The bottom line: confirm that your synthetic data is truly anonymized and cannot be reverse-engineered to reveal anything confidential.
Test Synthetic Data Usability
High-quality synthetic data should be usable in the same ways as real data. To ensure this, integrate the synthetic dataset into your typical analytics or model training pipeline and see if everything runs smoothly. Does the synthetic data conform to expected formats and schemas? Can your data ingestion process handle it? Also, check that basic statistical properties (like means, ranges, categorical levels) make sense and don’t cause errors in your analysis code. Essentially, this is a sanity check: if your team finds the synthetic data cumbersome or problematic to work with, its utility drops. In an ideal scenario, one could mix synthetic and real data seamlessly in an analysis, and consumers of the data (like data scientists or software systems) wouldn’t be able to tell a difference in terms of handling. If any issues arise (for example, synthetic timestamps that all fall on the exact hour, when real timestamps have minute-level variation), you might need to refine the generation process to better emulate real-world quirks. The synthetic data should meet the requirements of whatever project it’s used for – so test it in a proof-of-concept before committing to using it widely.
Monitor Model Performance on Synthetic Data
If you plan to train machine learning models using synthetic data (either solely or in combination with real data), evaluate how those models perform. After training a model on synthetic data, test it on a validation set of real data (if available) to see if the model’s predictions hold up. Compare this to a model trained on real data to gauge any differences. The synthetic data’s ultimate measure of quality is whether it enables models that perform well on real-world scenarios. For example, if a computer vision model trained on synthetic images can accurately identify objects in real photographs, that’s a good sign the synthetic images captured the right patterns. Conversely, if performance drops significantly, there may be some gap or artifact in the synthetic data that needs addressing. Always track key metrics (accuracy, recall, etc.) for models trained with synthetic inputs, and iteratively improve the data generation until those metrics are on par with using real data. Monitoring doesn’t stop at deployment – even after a model is in production, keep an eye on how it behaves on real-world data if it was trained partly on synthetic data, to ensure no drift or unexpected issues arise.
Compare Synthetic and Real Data Statistics
Perform a thorough statistical comparison between the synthetic dataset and the original real dataset (if you have or can use the real data for evaluation). This involves comparing distributions (are the histograms of key numerical features similar? do categorical frequencies align?), correlations (do relationships between variables hold?), and any known important patterns (seasonal trends in time-series, etc.). Many tools and metrics exist for this purpose, such as distribution overlap measures or the “train on synthetic, test on real” (TSTR) evaluation technique. The aim is to quantify how close the synthetic data is to the real data in terms of information content. If there are significant divergences, investigate whether those were intentional (for privacy, perhaps some noise was added) or unintentional. You want to ensure the synthetic data is “close enough” to be useful. For example, synthetic customer data should show similar purchasing trends by season as the real data; synthetic network traffic should exhibit similar peak hours as the real logs, and so on. Validating this gives confidence that conclusions drawn from synthetic data analysis would generalize to the real world.
Check Temporal and Sequential Consistency
This is especially important if your synthetic data includes any time-series or ordered data (e.g., sequences of events, longitudinal records). Ensure that the synthetic data respects the logical ordering and constraints of time. In a synthetic time-series, the values should evolve realistically over time (for instance, no sudden jumps that defy the patterns seen in real data unless those are intended outliers). If you have related datasets (like an accounts table and a transactions table in a bank scenario), make sure the synthetic data maintains consistency across them. An often-cited example: you wouldn’t want a synthetic transactions dataset that shows money being withdrawn from an account without the account balance changing accordingly in the synthetic accounts dataset. Such inconsistencies can creep in if data is generated separately for different tables or if the generative model doesn’t enforce referential integrity. To catch these issues, use domain-specific knowledge to verify constraints (e.g., a synthetic patient’s medical history should not have diagnoses dated before their birth date, etc.). Maintaining sequential integrity ensures that synthetic data remains realistic and credible in scenarios where order matters.
By following this checklist, you can approach synthetic data with the same rigor as real data. The overarching principle is “fit for purpose” – good synthetic data should serve your intended purpose effectively, whether that’s model training, software testing, or analytical research. It should uphold privacy and ethics while still providing useful signal. If it doesn’t, iterate on your synthetic data generation process until it does. Remember that synthetic data, like any powerful tool, must be used responsibly: with great (data) power comes great responsibility to ensure fairness, accuracy, and privacy.
Conclusion
Synthetic data and simulation techniques are fueling a new era of analytics by breaking through the traditional barriers of data scarcity and privacy. With generative models like GANs, diffusion models, and transformers, we can now create rich and realistic datasets on demand – enabling machine learning models to be trained where they previously could not, and allowing innovation to flourish in heavily regulated domains. From detecting fraud more effectively, to advancing healthcare research safely, to optimizing industrial operations, synthetic data is proving its value across a wide array of use cases.
However, as we embrace this powerful tool, it’s crucial to do so with care and oversight. Synthetic data should be rigorously validated to ensure it truly mimics reality and doesn’t lead us astray. Ethical considerations, such as avoiding bias and protecting privacy, remain paramount – the data may be fake, but its impact on real decisions is very real. By following best practices (like the quality and ethics checklist above) and adhering to guidelines for responsible AI (including thoughtful prompt engineering and bias mitigation), organizations can confidently harness synthetic data to drive analytics forward.
In summary, synthetic data offers a promising path to accelerate AI and analytics projects when real data is lacking or off-limits. It provides a sandbox for experimentation and a bridge over data gaps. Used wisely, synthetic data and generative models will continue to fuel innovation – empowering teams to explore “what if” scenarios, build better predictive models, and unlock insights while keeping privacy intact. It’s an exciting development in the data landscape, and those who master it will be well-positioned to lead in the era of AI-driven analytics.
References
- IBM – “What Is Synthetic Data?” IBM Think Blog (Rina Diane Caballar, Aug 2023). Explains the definition of synthetic data, generation techniques (statistical, GANs, transformers, VAEs, etc.), and highlights benefits and challenges (privacy, bias, etc.), with industry use cases in automotive, finance, healthcare, and manufacturing.ibm.com
- Alation – “What Is Synthetic Data in AI? Understanding Its Role and Benefits.” Alation Blog (Aug 20, 2024). Introduces synthetic data and why it matters for AI, noting Gartner’s prediction that by 2030 synthetic data will outpace real data in AI. Discusses overcoming data scarcity and privacy regulations with synthetic data.alation.com
- Lightly AI – “The Ultimate Guide to Synthetic Data Generation.” Lightly.ai Blog (Oct 27, 2025). A comprehensive guide covering types of synthetic data and techniques for generating them. Reviews deep generative models such as StyleGAN, diffusion models, VAEs, and transformers, and their applications in creating synthetic images, text, audio, and more. Also discusses future trends and the importance of fidelity and bias considerations.lightly.ai
- SAS – “A Checklist for Assessing Your Synthetic Data.” SAS Voices Blog (by Sundaresh Sankaran, Apr 1, 2025). Provides a step-by-step checklist for validating synthetic data quality and ensuring it is fit for purpose. Covers bias detection, data balancing, privacy protection (differential privacy), usability testing, model performance monitoring, statistical similarity checks, and sequential data consistency in synthetic datasets.blogs.sas.com
- AI Multiple – “Top 20+ Synthetic Data Use Cases.” AI Multiple Research (Cem Dilmegani, updated Sep 26, 2025). Outlines a wide range of use cases across industries for synthetic data. Includes examples in finance (fraud identification with rare event simulation), manufacturing (quality assurance and predictive maintenance with synthetic sensor data), healthcare (sharing data while preserving confidentiality), and more, illustrating the practical benefits of synthetic datasets in real-world scenarios.research.aimultiple.com